機械学習(Machine Learning)の勉強を始めました。第5回
今回は、前回(第4回)でご紹介した「アイリス花データ」を使用して、機械学習を実際に実行してみたいと思います。第3回でご紹介したように、機械学習には、大きく分けて、「Supervised Learning」、「Unsupervised Learning」、「Reinforcement Learning」の3種類がありました。ここでは、Supervised Learningをまず、ご紹介します。
Supervised Learningというのは、出力データにラベルを付けられるもので、例えば、ウイルスに感染しているか否か、スパムメールかどうか、花の種類といったように、結果にラベルを付けて分類できるデータを扱うものになります。アイリス花データの場合、変量として、がく片(sepal)の長さと幅、花びら(petal)長さと幅をcmで計測した4つの変量があり、ラベルとしては、アイリスの花の種類(Iris setosa/Iris versicolor/Iris virginica)の3種類がありました(詳しくは第4回をご参照ください)。
4つの変量がありますが、2次元の図にプロットする都合上、花びらの長さ[cm]と花びらの幅[cm]の2つの変量から、Pythonを使用してアイリスの花の種類を予測する機械学習モデルを作成します。Pythonを使用した機械学習の流れは、概ね以下になります。なお、Pythonのバージョンは3.5以上を想定しています。
- プロット出力用の関数を定義する。
- データを入力する。
- 入力データを、トレーニングデータとテストデータに分ける。
- トレーニングデータを使用してデータの標準偏差と平均値を求める。
- 標準偏差と平均値を使用して、トレーニングデータとテストデータを、それぞれ標準化する。
- 適切なモデル(Classifier)を選択する。
- トレーニングデータを使用して、モデルに機械学習させる。
- テストデータを使用して、ラベルの分類を行い、モデルを評価する。
- 学習結果を図にプロットする。
では、各ステップを詳しく見ていきましょう。
①プロット出力用の関数を定義する。
まず、対話形式ではなく、Pythonのスクリプトをファイルで用意します。Pythonスクリプトの先頭に以下の2行を添付しておくことをお勧めします。
| #!/usr/bin/env python # -*- coding:utf-8 -*- |
ここでは、以下のように、「plot_decision_regions」という名前のプロット出力用の関数を定義します。
import matplotlib.pyplot as plt
from matplotlib.colors import ListedColormap
def plot_decision_regions(X, y, classifier, test_idx=None, resolution=0.02):
# setup marker generator and color map
markers = ('s', 'x', 'o', '^', 'v')
colors = ('red', 'blue', 'lightgreen', 'gray', 'cyan')
cmap = ListedColormap(colors[:len(np.unique(y))])
# plot the decision surface
x1_min, x1_max = X[:, 0].min() - 1, X[:, 0].max() + 1
x2_min, x2_max = X[:, 1].min() - 1, X[:, 1].max() + 1
xx1, xx2 = np.meshgrid(np.arange(x1_min, x1_max, resolution),
np.arange(x2_min, x2_max, resolution))
Z = classifier.predict(np.array([xx1.ravel(), xx2.ravel()]).T)
Z = Z.reshape(xx1.shape)
plt.contourf(xx1, xx2, Z, alpha=0.4, cmap=cmap)
plt.xlim(xx1.min(), xx1.max())
plt.ylim(xx2.min(), xx2.max())
for idx, cl in enumerate(np.unique(y)):
plt.scatter(x=X[y == cl, 0], y=X[y == cl, 1],
alpha=0.8, c=cmap(idx),
marker=markers[idx], label=cl)
# highlight test samples
if test_idx:
# plot all samples
X_test, y_test = X[test_idx, :], y[test_idx]
plt.scatter(X_test[:, 0],
X_test[:, 1],
c='black',
alpha=0.5,
linewidths=1,
marker='o',
s=55, label='test set')
|
②データを入力する。
前回の第4回でご紹介した「アイリス花データ」は、オープンソースとして提供しているサイトのURLから、pandasライブラリーを使用して入力しましたが、実は、scikit-learningライブラリーの中に、アイリス花データがサポートされています。今回は、こちらのscikit-learning ライブラリーから、以下のようにデータを抽出します。変量の内、花びらの長さと幅だけを取り出すために、iris.dataの変量の内、2番目と3番目の要素だけを抽出してXの配列(150 x 2)に、ラベル(花びらの種類)を y(150 x 1)という配列に150サンプル分のデータを格納します。
from sklearn import datasets iris = datasets.load_iris() X = iris.data[:,[2,3]] y = iris.target |
③入力データを、トレーニングデータとテストデータに分ける。
scikit-learning.cross_validationライブラリーのtrain_test_split関数を使用して、
変量配列Xとラベル配列yについて、トレーニングデータとテストデータに分けます。変量配列Xを、それぞれ、X_train配列, X_test配列に分割し、ラベル配列yは、y_tarin配列, y_test配列へそれぞれ分割します。test_sizeのパラメータにより、テストデータの割合を指定できます。ここでは、0.3を指定することで、テストデータの割合を全体の30%と指定しています。全150サンプルの30%(= 45サンプル)がテストデータで、残りの105サンプルがトレーニングデータとなります。random_state=0を指定することにより、ランダムにトレーニングデータとテストデータを分割することができます。
from sklearn.cross_validation import train_test_split X_train, X_test, y_train, y_test = train_test_split(X,y, test_size=0.3, random_state=0) |
④トレーニングデータを使用してデータの標準偏差と平均値を求める。
sklearn.preprocessingライブラリーのStandardScaler関数を用いて、変量配列X_trainとX_testを標準化します。まず、標準化のための標準偏差と平均値は、トレーニングデータのみを使用して計算しなければなりません。fitメソッドを使用して以下のように行います。
from sklearn.preprocessing import StandardScaler sc = StandardScaler() sc.fit(X_train) |
⑤標準偏差と平均値を使用して、トレーニングデータとテストデータを、それぞれ標準化する。
次に、変量配列のトレーニングデータとテストデータを、transformメソッドを用いて、それぞれ標準化します。標準化した変量配列をそれぞれ、X_train_std, X_test_stdに格納します。
X_train_std = sc.transform(X_train) X_test_std = sc.transform(X_test) |
⑥適切なモデル(Classifier)を選択する。
様々なClassifierがPythonライブラーの中でサポートされています。線形データとして分類できる場合は、Perceptron, Adaptive Linear Neuron(Adaline),Logistic regulation, Support Vector Machine(SVM),Decision tree, Random forests, K-nearest neighbors(KNN)などがあります。「アイリス花データ」は線形データとして分類できるデータであるため、ここでは、最もシンプルなPerceptronのモデルを選択することとします。sklearn.linear_modelライブラリーのPerceptron関数を使用して以下のように記述します。
from sklearn.linear_model import Perceptron ppn = Perceptron(n_iter=40,eta0=0.1, random_state=0) |
ここで、n_iterは、「Epoch」と呼ばれる機械学習の試行回数で、eta0は、変量の各試行における係数の更新分Δω ( ω := ω + Δω)を調整する値です。Perceptronのモデルでは、データが完全に線形である時、試行を重ねる毎に、係数ωの値が最適化されて行きます。eta0の値が小さい程、最適値に収束しやすくなりますが、試行回数 n_iterの数を大きくなる傾向があり、eta0とn_iterの値のバランスを、うまく取る必要があります。
ラベルの予測値を、φ(z) で表すと、各学習試行のおける係数の更新Δωは、次のように表されます。

数式の詳細にご興味のある方は、以下の本の第2章を是非、読んでみてください。
「Python Machine Learning: Unlock Deeper Insights into Machine Learning With This Vital Guide to Cutting-edge Predictive Analytics」
Sebastian Raschka (著)
出版社: Packt Publishing (2015/9/23)
言語: 英語
ISBN-10: 1783555130
ISBN-13: 978-1783555130
⑦トレーニングデータを使用して、モデルに機械学習させる。
トレーニングデータにfitメソッドを適用して、学習させます。
ppn.fit(X_train_std, y_train) |
⑧テストデータを使用して、ラベルの分類を行い、モデルを評価する。
テストデータを使用して、ラベルの分類を行い、sklearn.metricsライブラリーのaccuracy_score関数を用いて、モデルの精度を評価します。
from sklearn.metrics import accuracy_score
y_pred = ppn.predict(X_test_std)
print('Accuracy: %.2f' % accuracy_score(y_test,y_pred))
出力結果は、以下のように91%の精度と表示されます。
Accuracy: 0.91
|
⑨学習結果を図にプロットする。
①で定義したplot_decision_regions関数を用いて、150サンプル全データについて、花びらの長さ[cm]を横軸に、花びらの幅[cm]を縦軸にした2次元領域にプロットします。●で囲まれた点がテストデータを用いて予測したラベルのデータとなります。テストデータ45サンプルの内、4サンプルが正しく分類できませんでした。図の内、赤の領域が今回の機械学習で得られたモデルにより予測したIris setosa(値:0)の領域です。青の領域は、機械学習モデルが予想したIris versicolor(値:1)の領域です。ライトグリーンの領域は、機械学習モデルが予測したIris virginica(値:2)の領域です。若干、正しく分類できていないデータがありますが、概ね、直線で分類ができていることがわかるかと思います。
import numpy as np
X_combined_std = np.vstack((X_train_std, X_test_std))
y_combined = np.hstack((y_train, y_test))
plot_decision_regions(X=X_combined_std, y=y_combined,
classifier=ppn, test_idx=range(105, 150))
plt.xlabel('petal length [standardized]')
plt.ylabel('petal width [standardized]')
plt.legend(loc='upper left')
plt.tight_layout()
plt.show()
|

全体を通してのコードは以下のようになります。なお、本コードの稼働環境は、Python3.5以上を想定しています。
import matplotlib.pyplot as plt
from matplotlib.colors import ListedColormap
def plot_decision_regions(X, y, classifier, test_idx=None, resolution=0.02):
# setup marker generator and color map
markers = ('s', 'x', 'o', '^', 'v')
colors = ('red', 'blue', 'lightgreen', 'gray', 'cyan')
cmap = ListedColormap(colors[:len(np.unique(y))])
# plot the decision surface
x1_min, x1_max = X[:, 0].min() - 1, X[:, 0].max() + 1
x2_min, x2_max = X[:, 1].min() - 1, X[:, 1].max() + 1
xx1, xx2 = np.meshgrid(np.arange(x1_min, x1_max, resolution),
np.arange(x2_min, x2_max, resolution))
Z = classifier.predict(np.array([xx1.ravel(), xx2.ravel()]).T)
Z = Z.reshape(xx1.shape)
plt.contourf(xx1, xx2, Z, alpha=0.4, cmap=cmap)
plt.xlim(xx1.min(), xx1.max())
plt.ylim(xx2.min(), xx2.max())
for idx, cl in enumerate(np.unique(y)):
plt.scatter(x=X[y == cl, 0], y=X[y == cl, 1],
alpha=0.8, c=cmap(idx),
marker=markers[idx], label=cl)
# highlight test samples
if test_idx:
# plot all samples
X_test, y_test = X[test_idx, :], y[test_idx]
plt.scatter(X_test[:, 0],
X_test[:, 1],
c='black',
alpha=0.5,
linewidths=1,
marker='o',
s=55, label='test set')
from sklearn import datasets
iris = datasets.load_iris()
X = iris.data[:,[2,3]]
y = iris.target
from sklearn.cross_validation import train_test_split
X_train, X_test, y_train, y_test = train_test_split(X,y, test_size=0.3, random_state=0)
from sklearn.preprocessing import StandardScaler
sc = StandardScaler()
sc.fit(X_train)
X_train_std = sc.transform(X_train)
X_test_std = sc.transform(X_test)
from sklearn.linear_model import Perceptron
ppn = Perceptron(n_iter=40,eta0=0.1, random_state=0)
ppn.fit(X_train_std, y_train)
from sklearn.metrics import accuracy_score
y_pred = ppn.predict(X_test_std)
print('Accuracy: %.2f' % accuracy_score(y_test,y_pred))
import numpy as np
X_combined_std = np.vstack((X_train_std, X_test_std))
y_combined = np.hstack((y_train, y_test))
plot_decision_regions(X=X_combined_std, y=y_combined,
classifier=ppn, test_idx=range(105, 150))
plt.xlabel('petal length [standardized]')
plt.ylabel('petal width [standardized]')
plt.legend(loc='upper left')
plt.tight_layout()
plt.show()
|
機械学習(Machine Learning)の勉強を始めました。第4回
| 今回は、機械学習のsupervised Learning のClassificationのモデルでよく、参照される「アイリス花データ」のご紹介と、Pythonのパッケージ・ライブラリーである pandaとmatplotlibの簡単な活用法をご紹介いたします。「アイリス花データ」とは、1936年の論文に、英国の統計学者・植物学者であったロナルド・フィッシャー氏が発表した多変量データです。 データセットは、アイリスの花の3種類(「Iris setosa」と「 Iris virginica」 と 「Iris versicolor」) を各々50サンプルずつ集めた計150のデータからなり、変数は、がく片の長さと幅、花びら長さと幅をcmで計測した4つの変量からなります。 この4つの変量の組合せを基にアイリスの花の種類(Iris setosa/Iris virginica/Iris versicolor)を分類するLDA(Linear Discriminant Analysis)モデルを開発したのでした。LDAモデルについては、後日、改めてご紹介いたします。 フィッシャーの「アイリス花データ」は、現在、オープン・ソースとして、以下のURLからダウンロードすることができます。 https://archive.ics.uci.edu/ml/machine-learning-databases/iris/iris.data Pythonのpandasライブラリーを使用して、ローカル・ファイルにダウンロードすることができます。保存するファイル名は、「irsi.data.csv」とします。 >>>import pandas as pd >>>df = pd.read_csv('https://archive.ics.uci.edu/ml/machine-learning-databases/iris/iris.data',header=None) >>>print(df) >>>df.to_csv("iris.data.csv",index=False,header=None) >>>quit() ローカルファイルとして、「irsi.data.csv」が保存されていることを確認します。内容は、Excel等で確認してください。 今度は、保存した「irsi.data.csv」ファイルをpandasライブラリーで読み取り、matplotlibライブラリーを使用して、プロットしてみましょう。 「アイリス花データ」は、最初の50行が「Iris-setosa」で、51行から100行までが、「Iris-vesicolor」で、101行目から150行までが、「Iris virginica」の順で並んでいます。変量が4つあるため、2次元にプロットするために、ここでは、第一番目の「 がく片の長さ[cm] 」と三番目の「 花びらの長さ[cm] 」の2つを変量に選び、プロットしてみます。 >>>import pandas as pd >>>import matplotlib.pyplot as plt >>>df = pd.read_csv('iris.data.csv',header=None) >>>X = df.iloc[:,[0,2]].values >>>plt.scatter(X[:50,0],X[:50,1],color='red',marker='o',label='setosa') >>>plt.scatter(X[50:100,0],X[50:100,1],color='blue',marker='x',label='versicolor') >>>plt.scatter(X[101:150,0],X[101:150,1],color='green',marker='s',label='virginica') >>>plt.xlabel('Sepal length') >>>plt.ylabel('Petal length') >>>plt.legend(loc='upper left') >>>plt.show() >>>quit() そうすると、以下のような図が表示されます。  若干、versicolorの種類とvirginicaの種類とが交差していますが、概ね、線形モデルで分類することが可能なのようです。次回は、この「アイリス花データ」を用いて、Supervised LearningによるClassificationのご紹介してみたいと思います。 参考までに、以下に、「アイリス花データ」の参考データを添付しました。 |
|


|
 Iris versicolor |
 Iris virginica |
Spectramap biplot of Fisher's iris data set
[cm] |
[cm] |
[cm] |
[cm] |
種類 |
|---|---|---|---|---|
| 5.1 | 3.5 | 1.4 | 0.2 | I. setosa |
| 4.9 | 3.0 | 1.4 | 0.2 | I. setosa |
| 4.7 | 3.2 | 1.3 | 0.2 | I. setosa |
| 4.6 | 3.1 | 1.5 | 0.2 | I. setosa |
| 5.0 | 3.6 | 1.4 | 0.2 | I. setosa |
| 5.4 | 3.9 | 1.7 | 0.4 | I. setosa |
| 4.6 | 3.4 | 1.4 | 0.3 | I. setosa |
| 5.0 | 3.4 | 1.5 | 0.2 | I. setosa |
| 4.4 | 2.9 | 1.4 | 0.2 | I. setosa |
| 4.9 | 3.1 | 1.5 | 0.1 | I. setosa |
| 5.4 | 3.7 | 1.5 | 0.2 | I. setosa |
| 4.8 | 3.4 | 1.6 | 0.2 | I. setosa |
| 4.8 | 3.0 | 1.4 | 0.1 | I. setosa |
| 4.3 | 3.0 | 1.1 | 0.1 | I. setosa |
| 5.8 | 4.0 | 1.2 | 0.2 | I. setosa |
| 5.7 | 4.4 | 1.5 | 0.4 | I. setosa |
| 5.4 | 3.9 | 1.3 | 0.4 | I. setosa |
| 5.1 | 3.5 | 1.4 | 0.3 | I. setosa |
| 5.7 | 3.8 | 1.7 | 0.3 | I. setosa |
| 5.1 | 3.8 | 1.5 | 0.3 | I. setosa |
| 5.4 | 3.4 | 1.7 | 0.2 | I. setosa |
| 5.1 | 3.7 | 1.5 | 0.4 | I. setosa |
| 4.6 | 3.6 | 1.0 | 0.2 | I. setosa |
| 5.1 | 3.3 | 1.7 | 0.5 | I. setosa |
| 4.8 | 3.4 | 1.9 | 0.2 | I. setosa |
| 5.0 | 3.0 | 1.6 | 0.2 | I. setosa |
| 5.0 | 3.4 | 1.6 | 0.4 | I. setosa |
| 5.2 | 3.5 | 1.5 | 0.2 | I. setosa |
| 5.2 | 3.4 | 1.4 | 0.2 | I. setosa |
| 4.7 | 3.2 | 1.6 | 0.2 | I. setosa |
| 4.8 | 3.1 | 1.6 | 0.2 | I. setosa |
| 5.4 | 3.4 | 1.5 | 0.4 | I. setosa |
| 5.2 | 4.1 | 1.5 | 0.1 | I. setosa |
| 5.5 | 4.2 | 1.4 | 0.2 | I. setosa |
| 4.9 | 3.1 | 1.5 | 0.2 | I. setosa |
| 5.0 | 3.2 | 1.2 | 0.2 | I. setosa |
| 5.5 | 3.5 | 1.3 | 0.2 | I. setosa |
| 4.9 | 3.6 | 1.4 | 0.1 | I. setosa |
| 4.4 | 3.0 | 1.3 | 0.2 | I. setosa |
| 5.1 | 3.4 | 1.5 | 0.2 | I. setosa |
| 5.0 | 3.5 | 1.3 | 0.3 | I. setosa |
| 4.5 | 2.3 | 1.3 | 0.3 | I. setosa |
| 4.4 | 3.2 | 1.3 | 0.2 | I. setosa |
| 5.0 | 3.5 | 1.6 | 0.6 | I. setosa |
| 5.1 | 3.8 | 1.9 | 0.4 | I. setosa |
| 4.8 | 3.0 | 1.4 | 0.3 | I. setosa |
| 5.1 | 3.8 | 1.6 | 0.2 | I. setosa |
| 4.6 | 3.2 | 1.4 | 0.2 | I. setosa |
| 5.3 | 3.7 | 1.5 | 0.2 | I. setosa |
| 5.0 | 3.3 | 1.4 | 0.2 | I. setosa |
| 7.0 | 3.2 | 4.7 | 1.4 | I. versicolor |
| 6.4 | 3.2 | 4.5 | 1.5 | I. versicolor |
| 6.9 | 3.1 | 4.9 | 1.5 | I. versicolor |
| 5.5 | 2.3 | 4.0 | 1.3 | I. versicolor |
| 6.5 | 2.8 | 4.6 | 1.5 | I. versicolor |
| 5.7 | 2.8 | 4.5 | 1.3 | I. versicolor |
| 6.3 | 3.3 | 4.7 | 1.6 | I. versicolor |
| 4.9 | 2.4 | 3.3 | 1.0 | I. versicolor |
| 6.6 | 2.9 | 4.6 | 1.3 | I. versicolor |
| 5.2 | 2.7 | 3.9 | 1.4 | I. versicolor |
| 5.0 | 2.0 | 3.5 | 1.0 | I. versicolor |
| 5.9 | 3.0 | 4.2 | 1.5 | I. versicolor |
| 6.0 | 2.2 | 4.0 | 1.0 | I. versicolor |
| 6.1 | 2.9 | 4.7 | 1.4 | I. versicolor |
| 5.6 | 2.9 | 3.6 | 1.3 | I. versicolor |
| 6.7 | 3.1 | 4.4 | 1.4 | I. versicolor |
| 5.6 | 3.0 | 4.5 | 1.5 | I. versicolor |
| 5.8 | 2.7 | 4.1 | 1.0 | I. versicolor |
| 6.2 | 2.2 | 4.5 | 1.5 | I. versicolor |
| 5.6 | 2.5 | 3.9 | 1.1 | I. versicolor |
| 5.9 | 3.2 | 4.8 | 1.8 | I. versicolor |
| 6.1 | 2.8 | 4.0 | 1.3 | I. versicolor |
| 6.3 | 2.5 | 4.9 | 1.5 | I. versicolor |
| 6.1 | 2.8 | 4.7 | 1.2 | I. versicolor |
| 6.4 | 2.9 | 4.3 | 1.3 | I. versicolor |
| 6.6 | 3.0 | 4.4 | 1.4 | I. versicolor |
| 6.8 | 2.8 | 4.8 | 1.4 | I. versicolor |
| 6.7 | 3.0 | 5.0 | 1.7 | I. versicolor |
| 6.0 | 2.9 | 4.5 | 1.5 | I. versicolor |
| 5.7 | 2.6 | 3.5 | 1.0 | I. versicolor |
| 5.5 | 2.4 | 3.8 | 1.1 | I. versicolor |
| 5.5 | 2.4 | 3.7 | 1.0 | I. versicolor |
| 5.8 | 2.7 | 3.9 | 1.2 | I. versicolor |
| 6.0 | 2.7 | 5.1 | 1.6 | I. versicolor |
| 5.4 | 3.0 | 4.5 | 1.5 | I. versicolor |
| 6.0 | 3.4 | 4.5 | 1.6 | I. versicolor |
| 6.7 | 3.1 | 4.7 | 1.5 | I. versicolor |
| 6.3 | 2.3 | 4.4 | 1.3 | I. versicolor |
| 5.6 | 3.0 | 4.1 | 1.3 | I. versicolor |
| 5.5 | 2.5 | 4.0 | 1.3 | I. versicolor |
| 5.5 | 2.6 | 4.4 | 1.2 | I. versicolor |
| 6.1 | 3.0 | 4.6 | 1.4 | I. versicolor |
| 5.8 | 2.6 | 4.0 | 1.2 | I. versicolor |
| 5.0 | 2.3 | 3.3 | 1.0 | I. versicolor |
| 5.6 | 2.7 | 4.2 | 1.3 | I. versicolor |
| 5.7 | 3.0 | 4.2 | 1.2 | I. versicolor |
| 5.7 | 2.9 | 4.2 | 1.3 | I. versicolor |
| 6.2 | 2.9 | 4.3 | 1.3 | I. versicolor |
| 5.1 | 2.5 | 3.0 | 1.1 | I. versicolor |
| 5.7 | 2.8 | 4.1 | 1.3 | I. versicolor |
| 6.3 | 3.3 | 6.0 | 2.5 | I. virginica |
| 5.8 | 2.7 | 5.1 | 1.9 | I. virginica |
| 7.1 | 3.0 | 5.9 | 2.1 | I. virginica |
| 6.3 | 2.9 | 5.6 | 1.8 | I. virginica |
| 6.5 | 3.0 | 5.8 | 2.2 | I. virginica |
| 7.6 | 3.0 | 6.6 | 2.1 | I. virginica |
| 4.9 | 2.5 | 4.5 | 1.7 | I. virginica |
| 7.3 | 2.9 | 6.3 | 1.8 | I. virginica |
| 6.7 | 2.5 | 5.8 | 1.8 | I. virginica |
| 7.2 | 3.6 | 6.1 | 2.5 | I. virginica |
| 6.5 | 3.2 | 5.1 | 2.0 | I. virginica |
| 6.4 | 2.7 | 5.3 | 1.9 | I. virginica |
| 6.8 | 3.0 | 5.5 | 2.1 | I. virginica |
| 5.7 | 2.5 | 5.0 | 2.0 | I. virginica |
| 5.8 | 2.8 | 5.1 | 2.4 | I. virginica |
| 6.4 | 3.2 | 5.3 | 2.3 | I. virginica |
| 6.5 | 3.0 | 5.5 | 1.8 | I. virginica |
| 7.7 | 3.8 | 6.7 | 2.2 | I. virginica |
| 7.7 | 2.6 | 6.9 | 2.3 | I. virginica |
| 6.0 | 2.2 | 5.0 | 1.5 | I. virginica |
| 6.9 | 3.2 | 5.7 | 2.3 | I. virginica |
| 5.6 | 2.8 | 4.9 | 2.0 | I. virginica |
| 7.7 | 2.8 | 6.7 | 2.0 | I. virginica |
| 6.3 | 2.7 | 4.9 | 1.8 | I. virginica |
| 6.7 | 3.3 | 5.7 | 2.1 | I. virginica |
| 7.2 | 3.2 | 6.0 | 1.8 | I. virginica |
| 6.2 | 2.8 | 4.8 | 1.8 | I. virginica |
| 6.1 | 3.0 | 4.9 | 1.8 | I. virginica |
| 6.4 | 2.8 | 5.6 | 2.1 | I. virginica |
| 7.2 | 3.0 | 5.8 | 1.6 | I. virginica |
| 7.4 | 2.8 | 6.1 | 1.9 | I. virginica |
| 7.9 | 3.8 | 6.4 | 2.0 | I. virginica |
| 6.4 | 2.8 | 5.6 | 2.2 | I. virginica |
| 6.3 | 2.8 | 5.1 | 1.5 | I. virginica |
| 6.1 | 2.6 | 5.6 | 1.4 | I. virginica |
| 7.7 | 3.0 | 6.1 | 2.3 | I. virginica |
| 6.3 | 3.4 | 5.6 | 2.4 | I. virginica |
| 6.4 | 3.1 | 5.5 | 1.8 | I. virginica |
| 6.0 | 3.0 | 4.8 | 1.8 | I. virginica |
| 6.9 | 3.1 | 5.4 | 2.1 | I. virginica |
| 6.7 | 3.1 | 5.6 | 2.4 | I. virginica |
| 6.9 | 3.1 | 5.1 | 2.3 | I. virginica |
| 5.8 | 2.7 | 5.1 | 1.9 | I. virginica |
| 6.8 | 3.2 | 5.9 | 2.3 | I. virginica |
| 6.7 | 3.3 | 5.7 | 2.5 | I. virginica |
| 6.7 | 3.0 | 5.2 | 2.3 | I. virginica |
| 6.3 | 2.5 | 5.0 | 1.9 | I. virginica |
| 6.5 | 3.0 | 5.2 | 2.0 | I. virginica |
| 6.2 | 3.4 | 5.4 | 2.3 | I. virginica |
| 5.9 | 3.0 | 5.1 | 1.8 | I. virginica |
機械学習(Machine Learning)の勉強を始めました。第3回
今回は、以下の本を読んでみて、機械学習の概要みたいなものを、少しだけ、まとめてみました。興味のある方は、以下の本の第1章を是非、読んでみてください。Pythonをこれから勉強したいと思われている方にもお勧めです。
「Python Machine Learning: Unlock Deeper Insights into Machine Learning With This Vital Guide to Cutting-edge Predictive Analytics」
Sebastian Raschka (著)
出版社: Packt Publishing (2015/9/23)
言語: 英語
ISBN-10: 1783555130
ISBN-13: 978-1783555130
この本によれば、どうも、機械学習は、大きく以下の3タイプに分類できるようです。
- Supervised Learning
- Unsupervised Learning
- Reinforcement Learning
まず、Supervised Learningというのは、出力データにラベルを付けられるもので、例えば、ウイルスに感染しているか否か、スパムメールかどうか、花の種類といったように、ラベルを付けて分類できるデータを扱うものになります。あらかじめトレーニング・データ(入力データとラベル出力の組合せ)を用意しておき、このトレーニングデータを基に機械学習アルゴリズムを適用することで、「predictive Model」を作成します。そして、新しい入力データに対して、このpredictive Modelにより、ラベルを予想します。これに対して、Unsupervised Learningというのは、出力データにラベルをつけることができないもので、分析してみたら、なんとなくデータの塊(クラスター)に分類できるようなものを指すようです。Reinforcement Learningというのは、「Agent」というのが常に「Environment」の状態を見張っていて、Environmentからの「Reward」が最大になるように「Action」を行う仕組みのようです。例えば、チェスなどのゲームで、「勝つ」というRewardを最大限にするように次の一手(Action)を計算するといったようなものです。
Supervised Learningを例に、以下に機械学習処理の流れを説明します。
- Preprocessing
- Learning
- Evaluation
- Prediction
(1) Preprocessing
どんなに優れた機械学習アルゴリズムを用いても、入力データが適切でないと、十分な能力を発揮することができません。そこで、機械学習では、入力データが機械学習アルゴリズムに良く適合するようにデータの前処理を行う必要があります。この前処理には、以下のようなものがあります。
- Feature Selection ( Sequential Backward Selectionなど)
- Feature Extraction (主成分分析,LDAなど)
- Dimension Reduction(上記以外に、kernel PCAなど)
- Scaling( Standardization, Regulation)
- Sampling
(2) Learning
- Model Selection
- どんなに優れた機械学習アルゴリズムを用いても、たった1つのモデルだけで、全ての入力データに対応することはできません。そこで、入力データの性質に合わせて、ベストなモデルを選択することが重要となります。代表的な機械学習アルゴリズムとして、Perceptron, Adaptive Linear Neuron(Adaline),Logistic regulation, Support Vector Machine(SVM),Radial Basis Function kernel(RBF kernel), Decision tree, Random forests, K-nearest neighbors(KNN)などがあります。
- Cross-Validation
- Performance Metrics
- Hyperparameter Optimization
(3)Evaluation
Rawデータを、そのまま全部、トレーニング・データとして用いるのではなく、Rawデータをトレーニング・データとテスト・データとにランダムに分割します。トレーニング・データとテストデータの比率は、60% : 40%, 70% : 30%,もしくは75% : 25% が一般的です。predictive Modelの作成には、Rawデータの内、このトレーニング・データだけを用いて、作成します。テスト・データはモデルの作成には使用しません。そして、評価の際に、テスト・データを用いて、評価を行います。評価の結果が良くない場合は、(2)Learningに戻って、モデルの選択の変更、各種パラメータのチューニングなどを行い、機械学習の精度を向上させます。
(4)Prediction
最終モデルが確定したら、全く新規の入力データを用いて、出力ラベルの予測を行います。
機械学習の勉強を始めました。第2回 〜 Pythonとパッケージ・ライブラリの導入 〜
第2回の今回は、機械学習のプログラミングに必要なPythonと、そのパッケージ・ライブラリーの導入方法について、ご案内いたします。
Pythonには、データ分析のために便利なパッケージ・ライブリーが豊富に揃っていて
機械学習に関係するものとしては、以下があります。
Numpy
SciPy
scikit-learn
matplotlib
pandas
また、Pythonには、パージョン2のものとバージョン3のものがあるのですが、バージョン2では、一部のパッケージ・ライブラリーが動かないため、最新のバージョン3を導入してください。Pythonを導入すると、pipコマンド(またはpip3コマンド)を使用して、上記のパッケージ・ライブラリーを導入することもできるのですが、Fortranのコンパイラーの用意が必要など、色々、手間がかかります。ところが、Anacondaを利用すると、パッケージ・ライブラリーの導入が簡単に行えるようになります。ここでは、Anacondaを利用したパッケージ・ライブラリーの導入をご紹介します。
導入環境として、(1)Windows (2)Mac (3)Linux の3通りについて順に説明します。
[1] WindowsにPython/Anacondaを導入する
(1)以下のURLから、最新のpython3インストーラーをダウンロードします。
https://www.python.org/downloads/
(2)ダウンロードした実行形式のインストーラーを実行します。
必ず、「Customize installation」を選択してください。「Install Now」を選択すると対話形式のPythonしか導入されず、DOSプロンプトからの実行ができなくなります。また、必ず、「Add Python 3.6 to PATH」にチェックしてください。

全てのオプションをチエックして、「Next」をクリックします。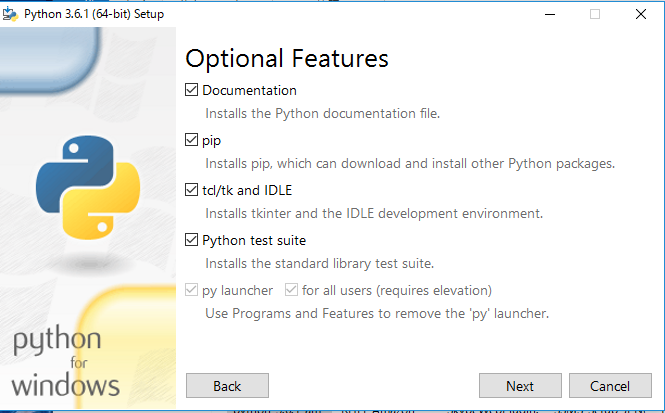
「Precompile standard library」をチェックして、「Install」をクリックします。

> python --version
と入力してください。正しいバージョンが表示されれば、Python3のインストールは
完了です。

(3)ANACONDAを以下のURLからインストラーをダウンロードします。
https://www.continuum.io/downloads
(4)ダウンロードした実行形式のインストーラーを実行します。画面の指示に従い、導入を進めてください。「Advanced Options」のところで、「Add Anaconda to my PATH enviromment variable」をチェックして、導入を完了します。

(5)Anacondaの導入が完了したら、DOSプロンプトを開いて、
> conda --version
と入力してください。正しいバージョンが表示されれば、Anacondaのインストール
は完了です。

(6) Anacondaを導入すると、パッケージ・ライブラーの導入が簡単に行えます。DOSプロンプトを開いて、以下を入力してください。
> conda install numpy
すると、以下の画面が表示されますので「y」を入力してEnterキーを押します。

パッケージ・ライブラリーの導入が完了したら、以下の手順で確認します。
まず、対話形式のPhthonを以下のコマンドで実行します。
> python
対話形式のpython3が起動されますので、以下を入力します。
>>> import numpy as np
>>> import scipy as sp
>>> import sklearn as sklearn
>>> import matplotlib as plt
>>> import pandas as pd
>>> quit()
エラーが表示されなければ、パッケージ・ライブラリーの導入は正常に完了しています。
Mac OSには、デフォルトで、python2.7が導入されていますが、ここでは、python3を導入する手順を説明します。
(1)以下のURLから、python3のインストーラをダウンロードします。
https://www.python.org/downloads/
(2)ダウンロードしたpython3のインストーラを実行します。
画面の指示に従って導入を完了してください。
(3)導入が完了したら、ターミナル・ウィンドウを開き、以下のコマンドを入力します。
$ python --version
正しくバージョンが表示されれば、インストールは終了です。
(4)次に、以下のURLから、Anacondaのインストーラをダウンロードします。
https://www.continuum.io/downloads
(5)ダウンロードしたAnacondaのインストーラを実行します。
画面の指示にしたがって、導入を完了してください。
(6)導入が完了したら、ターミナル・ウィンドウを開き、以下のコマンドを入力します。
$ conda --version
正しくバージョンが表示されれば、インストールは終了です。
(7) Anacondaを使用して機械学習に必要なパッケージ・ライブラリーを導入します。ターミナル・ウィンドウを開き、以下のコマンドを入力します。
$ conda install numpy
以下が表示されますので、”y”を入力してインストールを完了させます。

(8)パッケージ・ライブラリーが正しく導入されているかを確認します。
ターミナル・ウィンドウを開き、以下のコマンドを入力します。
$ python
対話形式のpython3が起動されますので、以下を入力します。
>>> import numpy as np
>>> import scipy as sp
>>> import sklearn as sklearn
>>> import matplotlib as plt
>>> import pandas as pd
>>> quit()
エラーが表示されなければ、パッケージ・ライブラリーの導入は正常に完了しています。
[3] LinuxにPython3/Anacondaを導入する
多くのLinuxでは、デフォルトで、python2.7が導入されていますが、ここでは、python3を導入する手順を説明します。
(1)以下のURLより、「Gzipped source tarball」のソースをダウンロードします。
https://www.python.org/downloads/
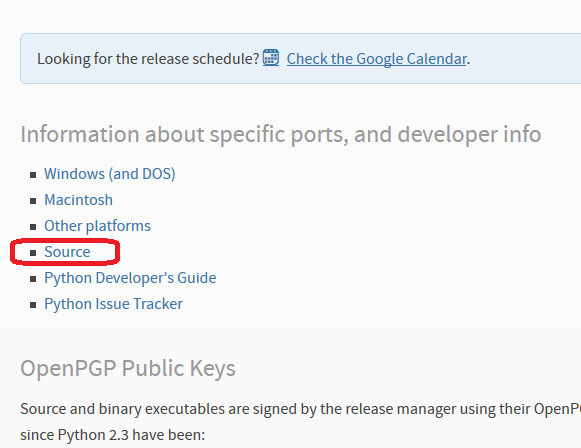

(2)以下のコマンドで、ダウンロードしたソースモジュールを解凍します。
$tar zxvf Python-3.6.0.tgz
(3)新しく作成されたディレクトリーに移動します。
$cd Pyhon-3.6.0
(4) $ ./configure
(5) $ make
(6) $sudo make install
(7) 以下のコマンドを実行し、正常にpython3が導入されたことを確認します。
$python --version
(8) 以下のURLからAnacondaのインストーラをダウンロードします。
https://www.continuum.io/downloads

(9) ダウンロードしたインストーラーを実行します。
$bash Anaconda3-4.3.1-Linux-x86_64.sh
(10)以下のコマンドで、Anacondaの導入を確認します。正しいバージョンが表示されます。
$ . .bashrc
$ conda --version
(11) 以下のコマンドで、パッケージ・ライブラリーを導入します。
$ conda install numpy
以下が表示されますので、”y”を入力してインストールを完了させます。

(12)パッケージ・ライブラリーが正しく導入されているかを確認します。
以下のコマンドを入力します。
$ python
対話形式のpython3が起動されますので、以下を入力します。
>>> import numpy as np
>>> import scipy as sp
>>> import sklearn as sklearn
>>> import matplotlib as plt
>>> import pandas as pd
>>> quit()
エラーが表示されなければ、パッケージ・ライブラリーの導入は正常に完了しています。
機械学習の勉強を始めました。第1回 〜 お薦めの書籍 〜
機械学習が得意な私の会社の上司に勧められて、先月から私も機械学習の勉強を始めました。上司によると、以下の書籍がお勧めとのことです。とても、良くまとまっているので、皆さんと情報共有したいと思いました。
機械学習の最初の一歩 "一番お勧めの書籍"
Python Machine Learning
https://www.amazon.co.jp/
機械学習関連で一番分かりやすいそうです。
前提知識
機械学習を習得するにあたっては、
以下が前提知識を得るために、お勧めの本だそうです。
統計
完全独習 統計学入門
https://www.amazon.co.jp/%E5%
完全独習 ベイズ統計学入門
https://www.amazon.co.jp/%E5%
多変量解析
まずはこの一冊から意味がわかる多変量解析
https://www.amazon.co.jp/%E3%
線形代数
まずはこの一冊から 意味がわかる線形代数
https://www.amazon.co.jp/%E3%
微分・積分
ゼロから学ぶ微分積分 (KS自然科学書ピ-ス)
https://www.amazon.co.jp/%E3%
機械学習系の有名な本
機械学習系で有名な本です。
Deep Learning
深層学習 (機械学習プロフェッショナルシリーズ)
https://www.amazon.co.jp/%E6%
非常にとっつきにくいそうですが関連書籍の中では一番正確な技術的な
イラストで学ぶ ディープラーニング (KS情報科学専門書)
https://www.amazon.co.jp/%E3%
イラストっていってますけどこれもとっつきにくいそうです、
言語処理
言語処理のための機械学習入門 (自然言語処理シリーズ)
https://www.amazon.co.jp/%E8%
トピックモデルによる統計的潜在意味解析 (自然言語処理シリーズ)
https://www.amazon.co.jp/%E3%
機械学習全般
わかりやすいパターン認識
https://www.amazon.co.jp/%E3%
パターン認識と機械学習 上
https://www.amazon.co.jp/%E3%
TensorFlow
TensorFlowで学ぶディープラーニング入門 ~畳み込みニューラルネットワーク徹底解説
https://www.amazon.co.jp/